On this page, we will explain in depth how to use Python's requests library to download large files and display the progress in real time during the download process. This will not only improve the user experience, but also help developers monitor the download status.
Sample Code
import requests
def download_file(url,save_file,chunk_size=8192):
try:
response = requests.get(url, stream=True)
response.raise_for_status()
total_size = int(response.headers.get('content-length', 0))
downloaded_size = 0
with open(save_file, 'wb') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
if chunk:
f.write(chunk)
downloaded_size += len(chunk)
if total_size == 0:
done = 0
else:
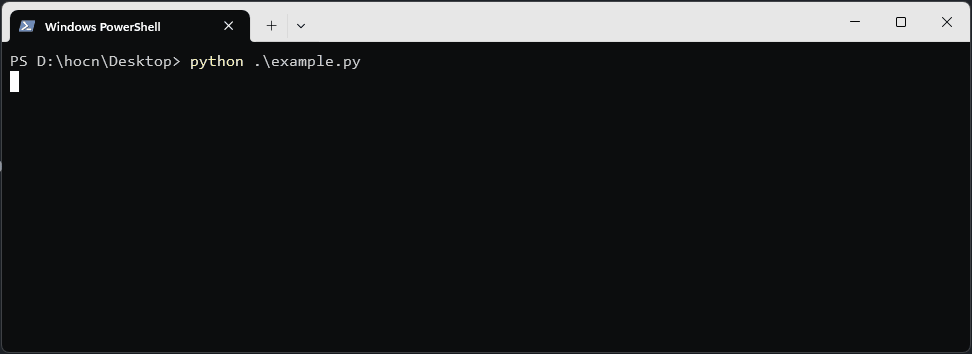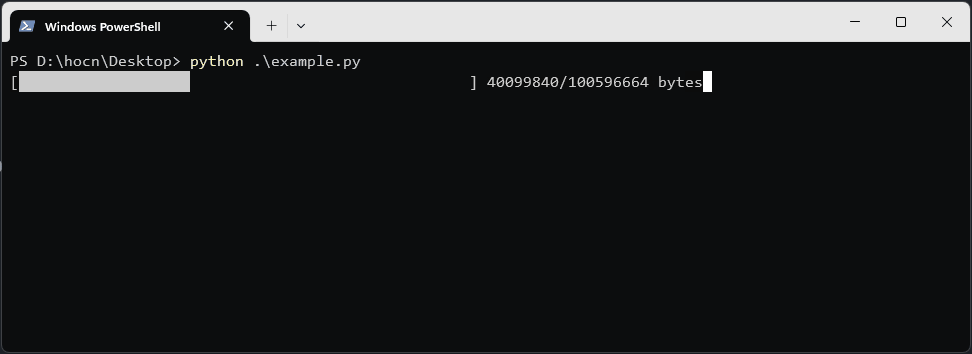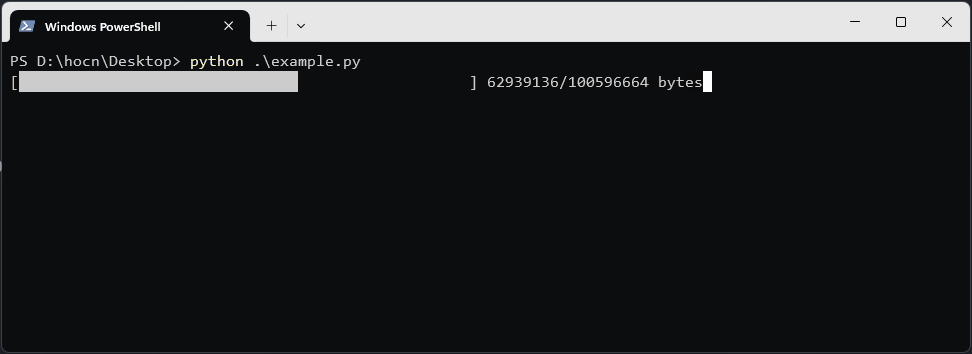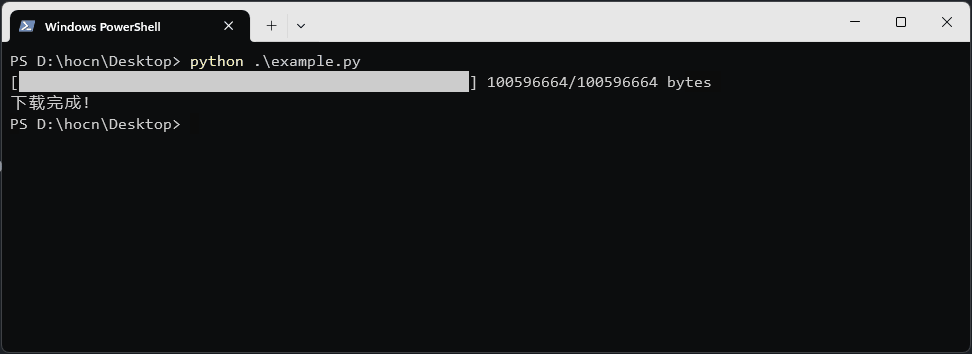
done = int(50 * downloaded_size / total_size)
print(f"\r[{'█' * done}{' ' * (50 - done)}] {downloaded_size}/{total_size} bytes", end='')
print("\n下载完成!")
except requests.exceptions.RequestException as e:
print(f"请求错误:{e}")
download_file('http://example.com/largefile.zip','largefile.zip')
Core code explanation
Get the size of the file to be downloaded
total_size = int(response.headers.get('content-length', 0))
The file size can be obtained through the Content-Length field in the HTTP request response header; this field may not exist (for example, the file is dynamically generated);
Show Progress
downloaded_size += len(chunk)
if total_size == 0:
done = 0
else:
done = int(50 * downloaded_size / total_size)
print(f"\r[{'█' * done}{' ' * (50 - done)}] {downloaded_size}/{total_size} bytes", end='')
The length of the progress bar is 50 units; the number of units downloaded and the remaining number can be obtained by calculation;
Download files piece by piece
Please refer to Reading Raw Stream Data with Requests